
PhyloFlask: Scaling Computational Bioinformatics & Phylogenetic Visualization
Challenging the Scale of Genomic Data
The explosive growth of Next-Generation Sequencing (NGS) technologies has created an unprecedented bottleneck in bioinformatics: the ability to efficiently analyze, summarize, and visualize massive genomic datasets. Traditional tools often fail to scale, buckling under the computational weight of large-scale phylogenetic profiling—a method critical for inferring the structural and functional properties of genes based on their presence or absence across complete genomes.
PhyloFlask was engineered to bridge this gap. Developed as an academic and scientific contribution at the BCCB Group (School of Informatics, AUTH), this robust software framework processes complex biological datasets, transforming raw genomic metrics into intuitive, multi-dimensional visual discoveries without requiring specialized, high-cost hardware.
High-Performance Data Engineering & Backend Architecture
Handling data that spans tens of thousands of bacterial and archaeal genomes requires strict optimization at the database and memory levels. The backend architecture of PhyloFlask was built from the ground up for maximum efficiency:
- Computationally Optimized Storage (CSR Matrices): To minimize memory footprints and drastic computational costs during graph processing, genomic relationship data is processed and stored as a Compressed Sparse Row (CSR) matrix. This allows the system to execute rapid matrix operations on massive datasets seamlessly.
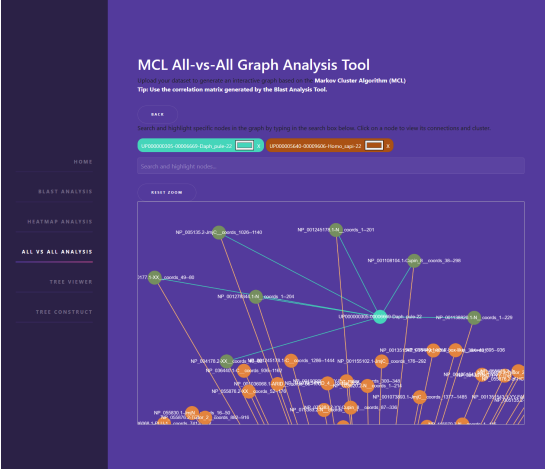
- Automated BLASTp Pipeline: The pipeline ingests arbitrary query datasets and species identifiers derived from raw BLASTp hits. It cross-references them against an indexed Reference Proteomes target database using COGENT-like identifiers, automatically structuring the output into functional correlation tables and feature matrices.
Dynamic Visual Analytics & Algorithmic Clustering
PhyloFlask abstracts complex data science pipelines into an interactive, real-time web ecosystem designed for researchers and scientists without a programming background:
- Enterprise-Grade Interactive Visualization: Leveraging a powerful stack of client-side libraries—including D3.js, ECharts, Plotly, Dash, and Cytoscape.js—the interface allows users to manipulate, customize, and explore heavy phylogenetic profiles and network graphs in real time.
- Markov Clustering (MCL) Integration: Beyond static visualization, the framework incorporates unsupervised machine learning. By applying the Markov Clustering (MCL) algorithm, PhyloFlask automatically groups species based on functional and structural similarities, bringing hidden evolutionary patterns and biological graphs to light.
Scientific Validation & Impact
Evaluated using real, large-scale genomic data provided by the Artificial Intelligence & Information Analysis Laboratory, PhyloFlask demonstrated exceptional throughput and zero performance degradation under heavy data loads.
Developed in collaboration with leading experts, including Dr. Christos Ouzounis, the platform serves as an essential tool in genomics. It accelerates biodiversity studies, facilitates rapid hypothesis generation for experimental validation, and uncovers high-confidence functional predictions for previously uncharacterized proteins.






